0
| 本文作者: 亞希伯恩?菲 | 2020-01-11 21:39 |
2019 年過(guò)去了,對(duì)于 AI 界而言,過(guò)去的一年可謂是“激流勇進(jìn)”的一年,一方面,整個(gè) AI 界的研究情緒高漲,推動(dòng)了 AI 技術(shù)的迅猛發(fā)展;另一方面,迅猛發(fā)展的背后,技術(shù)的局限性也日益凸顯,研究者們針對(duì)這些局限性也在積極探索,并各顯身手地提出了不計(jì)其數(shù)的新方法和研究方向。
但能從中脫穎而出并產(chǎn)生較大影響力的方法和研究方向,又有哪些?值得在未來(lái)一年中繼續(xù)深入探索的又有多少?
NLP 領(lǐng)域知名博主 Sebastian Ruder 博士就基于他的研究工作撰寫(xiě)了一份《2019年ML & NLP 領(lǐng)域十大研究熱點(diǎn)》的總結(jié)報(bào)道。
我們看他怎么說(shuō):
這篇文章匯總了我認(rèn)為 2019 年在ML 和 NLP 領(lǐng)域出現(xiàn)的十個(gè)最振奮人心和具有影響力的研究方向。針對(duì)每個(gè)熱點(diǎn),我會(huì)總結(jié)在過(guò)去一年所取得的主要進(jìn)展,簡(jiǎn)述為何我認(rèn)為其重要,并對(duì)未來(lái)做一個(gè)小小的展望。
以下是這十個(gè)研究熱點(diǎn):
通用無(wú)監(jiān)督預(yù)訓(xùn)練
“中獎(jiǎng)彩票”子網(wǎng)絡(luò)
神經(jīng)正切核
無(wú)監(jiān)督多語(yǔ)言學(xué)習(xí)
更魯棒的基準(zhǔn)數(shù)據(jù)集
用于科學(xué)研究的ML和NLP
修復(fù)NLG中的解碼錯(cuò)誤
增強(qiáng)預(yù)訓(xùn)練模型
高效、長(zhǎng)程的Transformer
更可靠的分析方法
1、發(fā)生了什么?
受到BERT (Devlin等人, 2019)及其變體大熱的影響,過(guò)去一年中,無(wú)監(jiān)督預(yù)訓(xùn)練是NLP 領(lǐng)域中的一個(gè)流行的研究方向。各種 BERT 變體用在了多模態(tài)的環(huán)境下,主要在涉及圖像,視頻以及文本環(huán)境(如下圖所示)。

VideoBERT(Sun等人,2019年),一種最新的BERT多模態(tài)變體,根據(jù)配方(上面)生成視頻“令牌”,并根據(jù)視頻令牌(下面)預(yù)測(cè)不同時(shí)間尺度的未來(lái)令牌。
無(wú)監(jiān)督預(yù)訓(xùn)練也開(kāi)始“入侵”以前由監(jiān)督方法占主導(dǎo)地位的領(lǐng)域。比如:
在生物學(xué)中,有研究者在蛋白質(zhì)序列上預(yù)訓(xùn)練Transformer語(yǔ)言模型(Rives等人,2019);
在計(jì)算機(jī)視覺(jué)中,也有研究者利用包括CPC(Hénaff 等人,2019),MoCo(He等人,2019)和PIRL(Misra&van der Maaten,2019)以及 BigBiGAN 生成器( Donahue&Simonyan,2019)在內(nèi)的自監(jiān)督方法提高 ImageNet 上的樣本效率和改善圖像生成;
在語(yǔ)音方面,使用多層CNN(Schneider等人,2019)或雙向CPC(Kawakami等人,2019)所學(xué)得的表示,在更少訓(xùn)練數(shù)據(jù)下的表現(xiàn)優(yōu)于當(dāng)前最好模型。
2、為什么重要?
無(wú)監(jiān)督預(yù)訓(xùn)練可以在帶有更少標(biāo)記樣本的數(shù)據(jù)上訓(xùn)練模型,這為以前無(wú)法滿足數(shù)據(jù)需求的許多不同領(lǐng)域中的應(yīng)用提供了新的可能性。
3、接下來(lái)是什么?
無(wú)監(jiān)督預(yù)訓(xùn)練仍有很大的進(jìn)步空間,盡管迄今為止它在單個(gè)領(lǐng)域都取得了很大進(jìn)步,未來(lái)將重點(diǎn)放在如何更緊密地集成多模態(tài)數(shù)據(jù),將是一個(gè)有趣的問(wèn)題。
1、發(fā)生了什么?
Frankle 和 Carbin 在2019 年的研究中發(fā)現(xiàn)了“中獎(jiǎng)彩票”現(xiàn)象,即一個(gè)隨機(jī)初始化、密集前饋網(wǎng)絡(luò)中的一些子網(wǎng)經(jīng)過(guò)極好的初始化,以至于單獨(dú)訓(xùn)練這些子網(wǎng)就可達(dá)到與訓(xùn)練整個(gè)網(wǎng)絡(luò)類似的準(zhǔn)確率,如下圖所示。
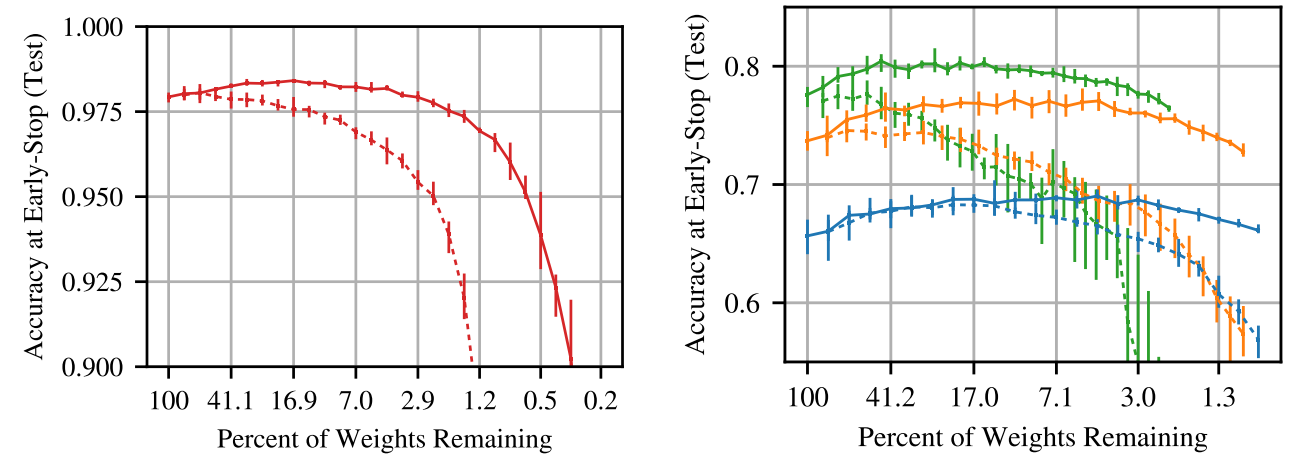
在不同的剪枝率下測(cè)試中獎(jiǎng)彩票子網(wǎng)絡(luò)(實(shí)線)與隨機(jī)采樣子網(wǎng)(虛線)的準(zhǔn)確性(Frankle&Carbin,2019)。
雖然最初的剪枝程序僅適用于小型視覺(jué)任務(wù),但后來(lái)的工作(Frankle等人,2019)在訓(xùn)練的早期而非初始化時(shí)應(yīng)用修剪,這使得剪枝程序可以找到更深層模型的小型子網(wǎng)。Yu等人,(2019)也在NLP和RL模型中發(fā)現(xiàn)了LSTM和Transformer的“中獎(jiǎng)彩票”初始化。
盡管“中獎(jiǎng)彩票”仍然很難找,但好消息是這些“中獎(jiǎng)彩票”似乎在不同數(shù)據(jù)集和優(yōu)化器之間具有可轉(zhuǎn)移性(Morcos等人,2019)。
2、為什么重要?
現(xiàn)今神經(jīng)網(wǎng)絡(luò)變得越來(lái)越大,用于訓(xùn)練和預(yù)測(cè)的成本也越來(lái)越高。若能識(shí)別出具有可比性能的小型子網(wǎng),便可以用更少的資源進(jìn)行訓(xùn)練和推理,從而可以加快模型的迭代速度,并為設(shè)備上計(jì)算和邊緣計(jì)算提供新的應(yīng)用場(chǎng)景。
3、接下來(lái)是什么?
目前找到“中獎(jiǎng)彩票”的代價(jià)仍然太高,無(wú)法在計(jì)算資源匱乏環(huán)境下提供實(shí)際的好處。修剪過(guò)程中不易受噪聲影響且更魯棒的一次性修剪方法或可緩解這種情況。
研究使“中獎(jiǎng)彩票”特別的原因,或許還能幫助我們更好地理解神經(jīng)網(wǎng)絡(luò)的初始化以及其學(xué)習(xí)動(dòng)力學(xué)。
1、發(fā)生了什么?
這個(gè)研究方向可能有點(diǎn)反直覺(jué),具體來(lái)說(shuō)就是無(wú)限寬的神經(jīng)網(wǎng)絡(luò)比窄的神經(jīng)網(wǎng)絡(luò)更容易從理論上進(jìn)行研究。
研究表明,在無(wú)限寬的情況下,神經(jīng)網(wǎng)絡(luò)可以近似為帶有神經(jīng)正切核 (Neural Tangent Kernel ,NTK; Jacot等人, 2018)的線性模型。下圖是其訓(xùn)練過(guò)程的動(dòng)態(tài)圖示。
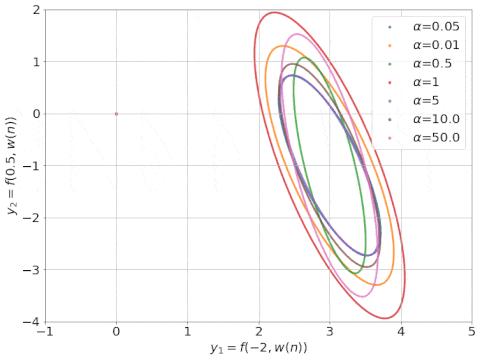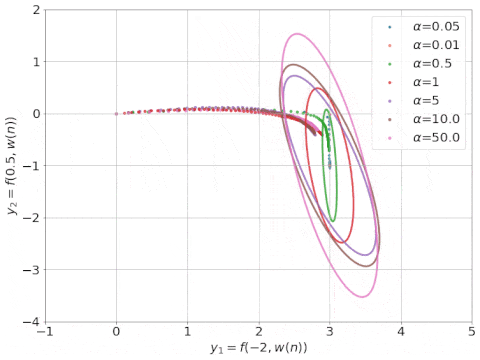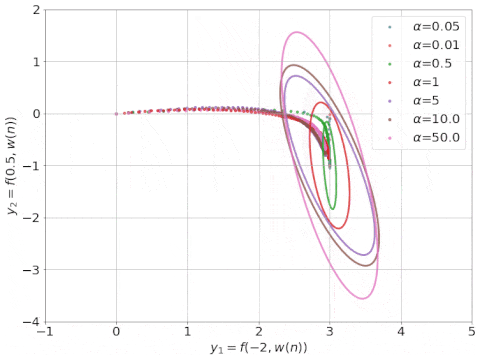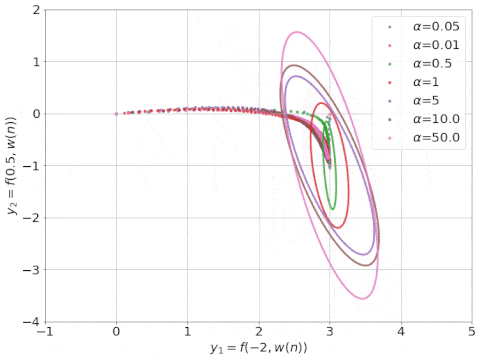
具有不同 α 因子的 NTK 線性模型的動(dòng)態(tài)學(xué)習(xí)過(guò)程, NTK 可視化為橢圓形(來(lái)源:Rajat的博客)。
然而在實(shí)踐中,這些模型的表現(xiàn)不如有限深度模型(Novak等人,2019; Allen-Zhu等人,2019; Bietti&Mairal,2019),這限制了將新發(fā)現(xiàn)應(yīng)用于標(biāo)準(zhǔn)方法。
但最近的工作(Li 等人,2019;Arora 等人,2019)已大大縮小了與標(biāo)準(zhǔn)方法的性能差距(具體請(qǐng)參閱Chip Huyen針對(duì)其他相關(guān)的NeurIPS 2019論文寫(xiě)的博文,https://huyenchip.com/2019/12/18/key-trends-neurips-2019.html)。
2、為什么重要?
NTK也許是我們分析神經(jīng)網(wǎng)絡(luò)理論行為的最強(qiáng)大的工具,盡管它有其局限性,即實(shí)際的神經(jīng)網(wǎng)絡(luò)仍然比 NTK 對(duì)應(yīng)的方法的表現(xiàn)更好。
雖然到目前為止該研究方向理論上的見(jiàn)解還沒(méi)有轉(zhuǎn)化為經(jīng)驗(yàn)上的收獲,但這可能有助于我們打開(kāi)深度學(xué)習(xí)的黑匣子。
3、下一步是什么?
與標(biāo)準(zhǔn)方法的差距,似乎主要由于此類方法的有限寬度所導(dǎo)致,這些可能會(huì)在將來(lái)的工作中體現(xiàn)出來(lái)。這還將有望幫助將無(wú)限寬度限制下的一些理論上的見(jiàn)解轉(zhuǎn)換得更符合實(shí)際設(shè)置。
最終,NTK 或可為我們闡明神經(jīng)網(wǎng)絡(luò)的訓(xùn)練動(dòng)力學(xué)和泛化行為。
1、發(fā)生了什么?
多年來(lái),跨語(yǔ)言表示主要集中在單詞級(jí)別上的表示。在無(wú)監(jiān)督預(yù)訓(xùn)練的基礎(chǔ)上,過(guò)去的一年見(jiàn)證了諸如多語(yǔ)言BERT,XLM(Conneau&Lample,2019)和 XLM-R(Conneau等人,2019)等跨語(yǔ)言模型的深入發(fā)展。
雖然這些模型沒(méi)有使用任何明確的跨語(yǔ)言信號(hào),但它們即便在沒(méi)有共享詞匯或聯(lián)合訓(xùn)練情況下實(shí)現(xiàn)的跨語(yǔ)言的泛化效果,依舊令人驚訝(Artetxe 等人,2019; Karthikeyan等人,2019; Wu等人,2019 )。
這些深度模型還帶來(lái)了無(wú)監(jiān)督 MT 的改進(jìn)(Song 等人,2019; Conneau&Lample,2019),在前年(2018年)取得了長(zhǎng)足的進(jìn)步基礎(chǔ)上,在去年又從統(tǒng)計(jì)和神經(jīng)方法的更原則性結(jié)合中,獲得了改進(jìn)( Artetxe 等人,2019)。
另一個(gè)令人振奮的進(jìn)展則是,從現(xiàn)成的預(yù)訓(xùn)練英語(yǔ)表示中引伸出深層多語(yǔ)言模型(Artetxe等人,2019; Tran,2020),如下圖所示。
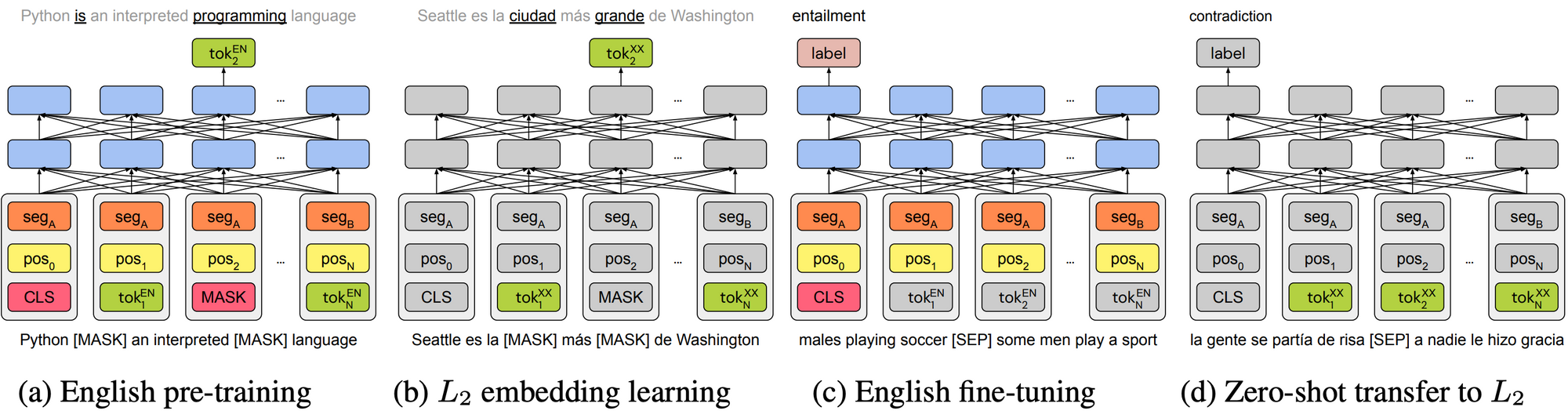
Artetxe等人(2019)的單語(yǔ)種遷移方法的四步驟。
2、為什么重要?
即用型跨語(yǔ)言表示使訓(xùn)練模型所需的非英語(yǔ)語(yǔ)言樣本更少。此外,若可以使用英語(yǔ)標(biāo)記的數(shù)據(jù),則這些方法可實(shí)現(xiàn)幾乎免費(fèi)的零樣本轉(zhuǎn)移。最終,這些方法可以幫助我們更好地理解不同語(yǔ)言之間的關(guān)系。
3、下一步是什么?
目前尚不清楚為什么這些方法在沒(méi)有任何跨語(yǔ)言監(jiān)督的情況下如此有效。更好地了解這些方法的工作方式,將使我們能夠設(shè)計(jì)出功能更強(qiáng)大的方法,還有可能揭示出關(guān)于不同語(yǔ)言結(jié)構(gòu)的一些見(jiàn)解。
另外,我們不僅應(yīng)該專注于零樣本轉(zhuǎn)移,還應(yīng)該在目標(biāo)語(yǔ)言中考慮小樣本學(xué)習(xí)問(wèn)題。
當(dāng)下的發(fā)展,定有些烏七八糟的事情。
—Nie et al. (2019) ,引自 Shakespeare《哈姆雷特》(There is something rotten in the state of Denmak,丹麥國(guó)里,定有些烏七八糟的事)
1、、發(fā)生了什么?
針對(duì)最近新開(kāi)發(fā)出來(lái)的 NLP 數(shù)據(jù)集如 HellaSWAG (Zellers et al., 2019) ,當(dāng)前最先進(jìn)的模型也難以應(yīng)對(duì)。
研究者需要人工過(guò)濾樣本,僅明了地保留那些當(dāng)前最先進(jìn)模型處理失敗的樣本(請(qǐng)參閱下面的示例)。可以重復(fù)多次“人在回環(huán)”的對(duì)抗管理過(guò)程,來(lái)創(chuàng)建對(duì)當(dāng)前方法更具挑戰(zhàn)性的數(shù)據(jù)集,例如在最近提出的的 Adversarial NLI(Nie等人,2019)基準(zhǔn)測(cè)試中,就可以實(shí)現(xiàn)這一點(diǎn)。
 來(lái)自HellaSWAG數(shù)據(jù)集的多項(xiàng)選擇句補(bǔ)全示例即使對(duì)于最新的模型也很難回答。大多數(shù)困難的例子都位于一個(gè)復(fù)雜的“戈?duì)柕侣蹇藚^(qū)”,大致由三個(gè)上下文句子和兩個(gè)生成的句子組成(Zellers等人,2019)。
來(lái)自HellaSWAG數(shù)據(jù)集的多項(xiàng)選擇句補(bǔ)全示例即使對(duì)于最新的模型也很難回答。大多數(shù)困難的例子都位于一個(gè)復(fù)雜的“戈?duì)柕侣蹇藚^(qū)”,大致由三個(gè)上下文句子和兩個(gè)生成的句子組成(Zellers等人,2019)。
2、為什么重要?
許多研究人員已經(jīng)觀察到,當(dāng)前的NLP模型并沒(méi)有學(xué)到預(yù)期學(xué)到的內(nèi)容,而是采用淺層啟發(fā)并結(jié)合數(shù)據(jù)中的表層線索的方法(又稱為“聰明漢斯時(shí)刻”)。隨著數(shù)據(jù)集變得更加魯棒難學(xué),我們希望(能迫使)模型最終去學(xué)習(xí)數(shù)據(jù)中真正的潛在關(guān)系。
3、下一步是什么?
隨著模型變得更好,大多數(shù)數(shù)據(jù)集將需要不斷改進(jìn),否則就會(huì)很快過(guò)時(shí)。專用的基礎(chǔ)設(shè)施和工具對(duì)于促進(jìn)此過(guò)程很有必要。
此外,應(yīng)在數(shù)據(jù)集上先運(yùn)行合適的基準(zhǔn)方法,例如,包括使用不同數(shù)據(jù)變體(例如輸入不完整)的簡(jiǎn)單方法和模型,以使數(shù)據(jù)集的初始版本盡可能魯棒。
1、發(fā)生了什么?
機(jī)器學(xué)習(xí)已在基礎(chǔ)科學(xué)問(wèn)題上取得了一些重大進(jìn)展。例如,有研究(Pfau等人,2019)將深層神經(jīng)網(wǎng)絡(luò)應(yīng)用于蛋白質(zhì)折疊和多電子Schr?dinger方程。
在自然語(yǔ)言處理方面,即便是一些標(biāo)準(zhǔn)方法,在結(jié)合領(lǐng)域?qū)I(yè)知識(shí)后所產(chǎn)生的影響也能令人興奮。其中有一項(xiàng)研究使用詞嵌入技術(shù)來(lái)分析材料科學(xué)文獻(xiàn)中的潛在知識(shí)(Tshitoyan等人,2019),以將其用于預(yù)測(cè)材料是否具有某些特性(請(qǐng)參見(jiàn)下圖)。
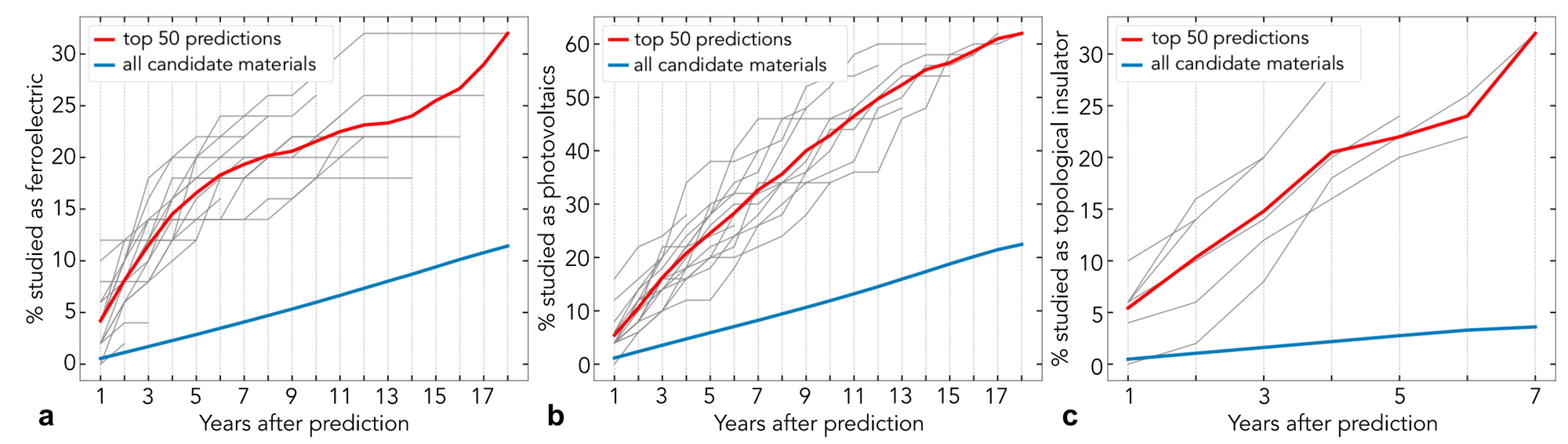
使用在不同時(shí)間段的摘要上訓(xùn)練得到的詞嵌入預(yù)測(cè)將在未來(lái)的摘要中研究哪些材料作為鐵電材料(a),光伏材料(b)和拓?fù)浣^緣體(c ),與所有候選材料相比,更有可能對(duì)前50個(gè)預(yù)測(cè)材料進(jìn)行研究(Tshitoyan等人,2019)。
在生物學(xué)中,許多數(shù)據(jù)(例如基因和蛋白質(zhì))本質(zhì)上是序列數(shù)據(jù)。因此,自然可將LSTM和Transformers等NLP方法用于蛋白質(zhì)分類(Strodthoff等人,2019; Rives等人,2019)。
2、為什么重要?
科學(xué)可以說(shuō)是ML最有影響力的應(yīng)用領(lǐng)域之一。解決方案可對(duì)許多其他領(lǐng)域產(chǎn)生重大影響,并且有助于解決實(shí)際問(wèn)題。
3、下一步是什么?
從對(duì)物理問(wèn)題中的能量建模(Greydanus等人,2019)到求解微分方程(Lample&Charton,2020),ML方法一直在科學(xué)的新應(yīng)用中不斷擴(kuò)大。看看2020年在哪種問(wèn)題上的應(yīng)用將會(huì)產(chǎn)生最大的影響也是挺有趣的。
1、發(fā)生了什么?
盡管功能越來(lái)越強(qiáng)大,但自然語(yǔ)言生成(NLG)模型仍然經(jīng)常產(chǎn)生重復(fù)或胡言亂語(yǔ),如下圖所示。

GPT-2使用光束搜索和純(貪婪)采樣產(chǎn)生的重復(fù)(藍(lán)色)和胡言亂語(yǔ)(紅色)(Holtzman等人,2019)。
事實(shí)表明,這主要是最大似然訓(xùn)練的結(jié)果。我很高興看到已經(jīng)有一些旨在改善這一點(diǎn)的研究工作,與此同時(shí),在建模方面也取得了一些進(jìn)展。這種改進(jìn)或者通過(guò)采用新采樣的方法獲得,例如核采樣(Holtzman等人,2019),或者通過(guò)使用新的損失函數(shù)獲得(Welleck等人,2019)。
另一個(gè)令人驚訝的發(fā)現(xiàn)是,更好的搜索不會(huì)帶來(lái)更好的生成:當(dāng)前模型在某種程度上依賴于不完善搜索和波束搜索錯(cuò)誤。在機(jī)器翻譯的情況下,精確搜索通常會(huì)返回空翻譯(Stahlberg&Byrne,2019)。這表明搜索和建模方面的進(jìn)步必須齊頭并進(jìn)。
2、為什么重要?
自然語(yǔ)言生成是NLP中最普遍的任務(wù)之一。在 NLP 和 ML 研究中,大多數(shù)論文都集中在改進(jìn)模型上,而流程中的其他部分通常被忽略。
對(duì)于NLG,需要注意的是,我們的模型仍然存在缺陷,并且可以通過(guò)修復(fù)搜索或訓(xùn)練過(guò)程來(lái)改善輸出。
3、下一步是什么?
盡管有更強(qiáng)大的模型以及遷移學(xué)習(xí)在NLG的成功應(yīng)用(Song等人,2019; Wolf等人,2019),模型預(yù)測(cè)仍然存在許多瑕疵,識(shí)別和理解此類瑕疵的成因,將是未來(lái)重要的研究方向。
1、發(fā)生了什么?
在過(guò)去一年,我很高興看到研究者為預(yù)訓(xùn)練模型提出了增加新功能的方法。一些方法用知識(shí)庫(kù)增強(qiáng)了預(yù)訓(xùn)練模型,以改善實(shí)體名稱建模(Liu等人,2019)和事實(shí)回憶(Logan 等人,2019)。其它研究則使預(yù)訓(xùn)練模型能夠通過(guò)訪問(wèn)許多預(yù)定義的可執(zhí)行的程序,來(lái)執(zhí)行簡(jiǎn)單的算術(shù)推理(Andor 等人,2019)。
由于大多數(shù)模型具有較弱的歸納偏差并可以從數(shù)據(jù)中學(xué)習(xí)大多數(shù)知識(shí),因此增強(qiáng)預(yù)訓(xùn)練模型的另一種方法是增強(qiáng)訓(xùn)練數(shù)據(jù)本身,例如捕捉常識(shí)(Bosselut等人,2019),如下圖所示。
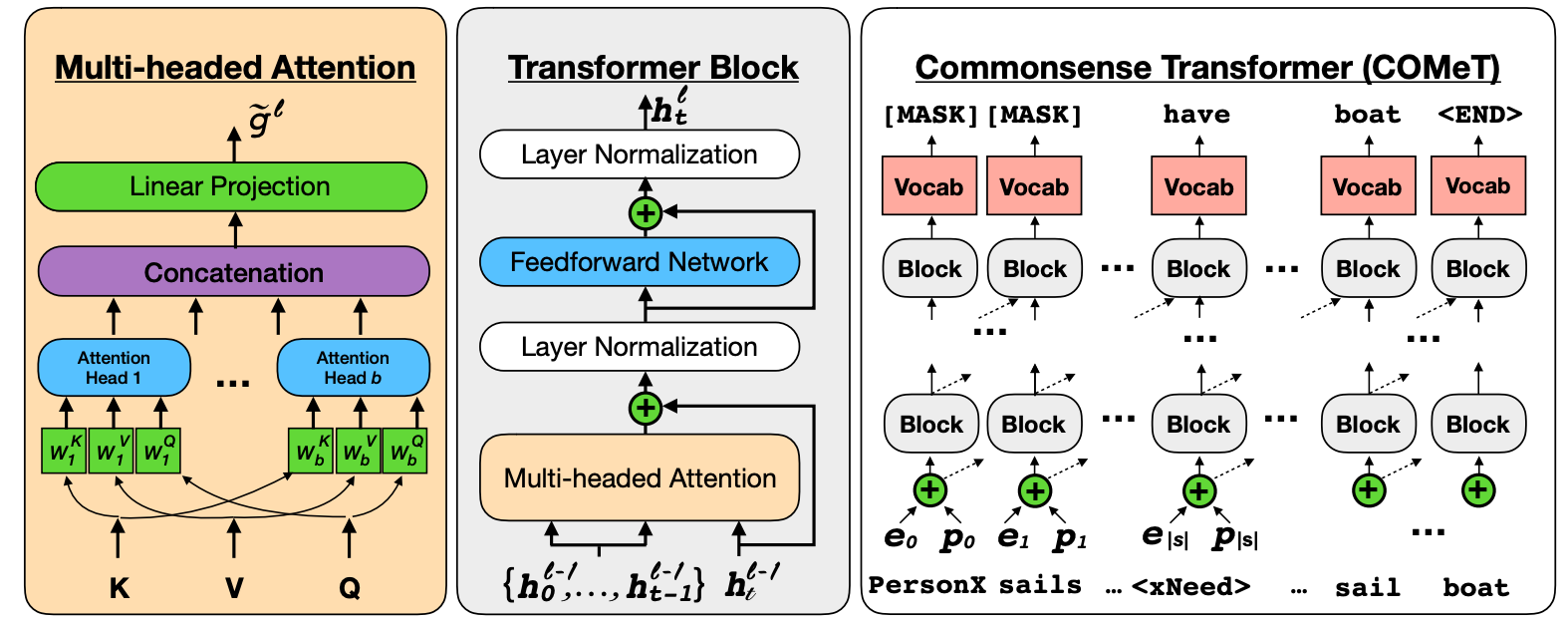
具有多頭注意的標(biāo)準(zhǔn)Transformer。經(jīng)過(guò)訓(xùn)練的模型可以根據(jù)給定的主題和關(guān)系來(lái)預(yù)測(cè)知識(shí)庫(kù)三元組的對(duì)象(Bosselut等人,2019)。
2、為什么重要?
模型正變得越來(lái)越強(qiáng)大,但是模型無(wú)法從文本中學(xué)到很多東西。特別是在處理更復(fù)雜的任務(wù)時(shí),可用數(shù)據(jù)可能十分有限,以至于無(wú)法使用事實(shí)或常識(shí)來(lái)學(xué)得顯式的推理,并且可能經(jīng)常需要更強(qiáng)的歸納偏差。
3、下一步是什么?
隨著將模型應(yīng)用于更具挑戰(zhàn)性的問(wèn)題,對(duì)組合進(jìn)行修改將變得越來(lái)越有必要。將來(lái),我們可能會(huì)結(jié)合功能強(qiáng)大的預(yù)訓(xùn)練模型和可學(xué)習(xí)的組合程序(Pierrot等人,2019)。
1、發(fā)生了什么?
過(guò)去一年中,Transformer 架構(gòu)實(shí)現(xiàn)了一些改進(jìn)(Vaswani等人,2017)。例如Transformer-XL(Dai等人,2019)和Compressive Transformer(Rae等人,2020)使該架構(gòu)能夠更好地捕獲長(zhǎng)程依賴關(guān)系。
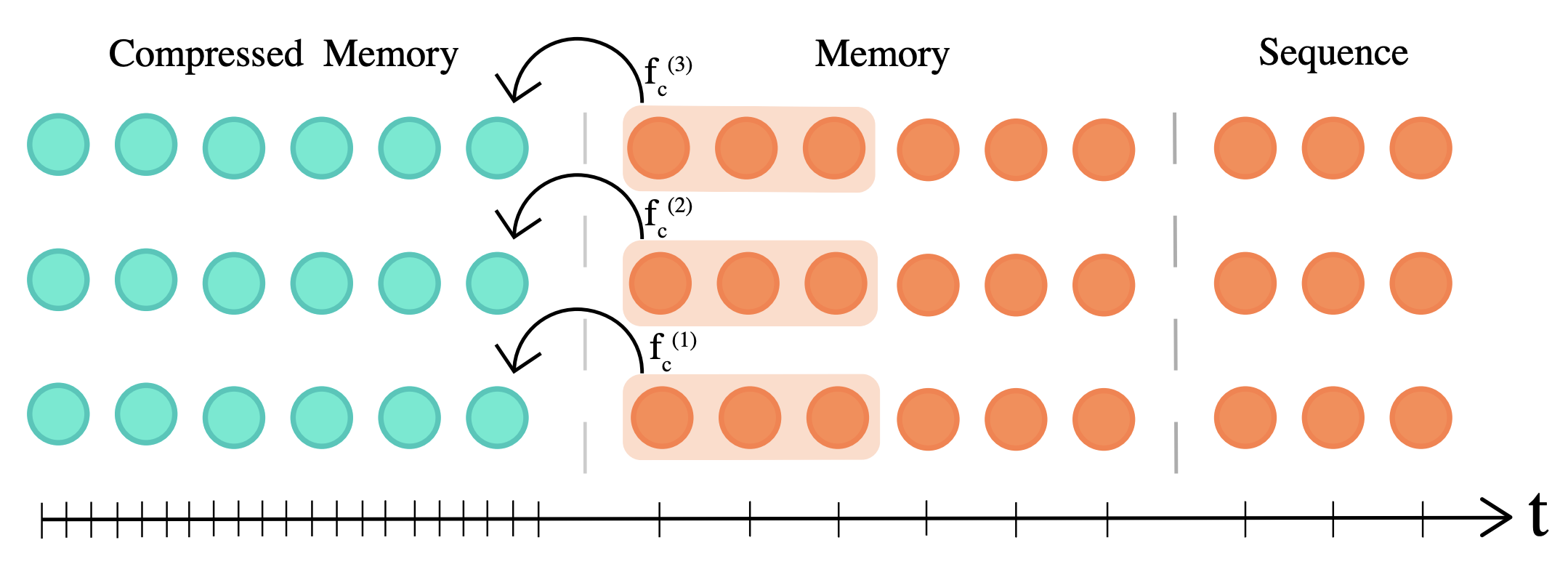
壓縮的Transformer將(細(xì)粒度內(nèi)存的)過(guò)去的激活壓縮為一個(gè)更粗糙的壓縮內(nèi)存(Rae等人,2020)。
與此同時(shí),許多方法試圖通過(guò)使用不同的(通常是稀疏的)注意力機(jī)制來(lái)提高 Transformer 的效率,例如利用自適應(yīng)稀疏注意力(Correia等人,2019),自適應(yīng)注意力跨度(Sukhbaatar等人,2019),乘積鍵注意力( Lample等人,2019),以及局部敏感哈希(Kitaev等人,2020)等方法,來(lái)提高 Transformer 效率。
在基于Transformer 的預(yù)訓(xùn)練方面,出現(xiàn)了更有效的變體,例如使用參數(shù)共享的ALBERT(Lan等人,2020)和使用了更有效的預(yù)訓(xùn)練任務(wù)的ELECTRA(Clark等人,2020)。不過(guò),也有一些預(yù)訓(xùn)練模型雖然不使用Transformer,但是更加有效,例如一元文件模型 VAMPIRE(Gururangan等人,2019)和基于QRNN的MultiFiT(Eisenschlos等人,2019)。
該領(lǐng)域的另一個(gè)趨勢(shì)是,將大型 BERT 模型提煉成較小的模型(Tang等人,2019; Tsai等人,2019; Sanh等人,2019)。
2、為什么重要?
Transformer 架構(gòu)自提出以來(lái),一直極具影響力。它是NLP中大多數(shù)最新模型的組成部分,并且已成功應(yīng)用于許多其他領(lǐng)域(請(qǐng)參見(jiàn)第1和第6節(jié))。因此,對(duì) Transformer 體系結(jié)構(gòu)的任何改進(jìn)都有可能產(chǎn)生強(qiáng)烈的“波紋效應(yīng)”。
3、下一步是什么?
從業(yè)者從 Transformer 取得的以上改進(jìn)中獲益可能還需要一段時(shí)間,但是鑒于預(yù)訓(xùn)練模型的普遍性和易用性,這段時(shí)間也不會(huì)太長(zhǎng)。
總體而言,強(qiáng)調(diào)效率的模型架構(gòu)有希望繼續(xù)成為關(guān)注的焦點(diǎn),稀疏性則是關(guān)鍵趨勢(shì)之一。
1、發(fā)生了什么?
過(guò)去的一年中,ML 和 NLP 研究的主要趨勢(shì)之一是,分析模型的論文數(shù)量在增加。
實(shí)際上,過(guò)去的一年中我最喜歡的幾篇論文,就是這類分析模型的論文。2019 年早些時(shí)候,Belinkov 和 Glass 曾針對(duì)分析方法做了一份非常出色的調(diào)查報(bào)告。
在我的印象中,過(guò)去一年首次出現(xiàn)很多致力于分析單個(gè)模型 BERT 的論文的現(xiàn)象(此類論文被稱為 BERTology)。在這種情況下,旨在了解模型是否通過(guò)預(yù)測(cè)某些屬性來(lái)捕獲形態(tài)、語(yǔ)法等的探針,已成為一種常用工具(參見(jiàn)下圖)。
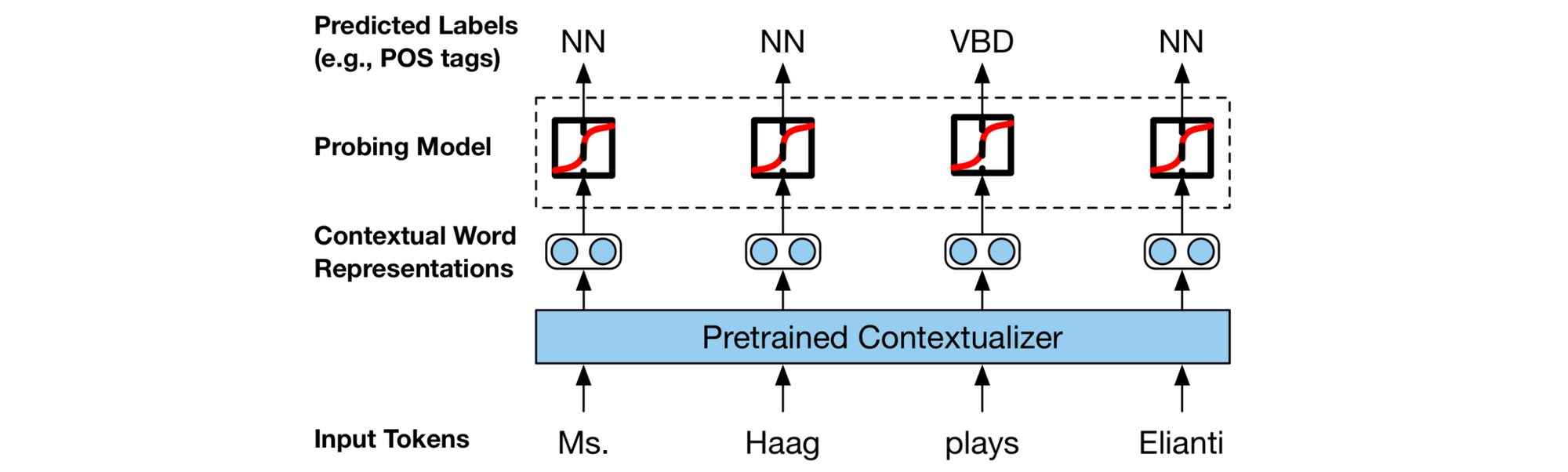 用于研究表示中語(yǔ)言知識(shí)的探針的設(shè)置(Liu等人,2019)。
用于研究表示中語(yǔ)言知識(shí)的探針的設(shè)置(Liu等人,2019)。
我特別贊賞使探針更可靠的論文(Liu 等人,2019 ; Hewitt&Liang,2019)。而可靠性也正是對(duì)話領(lǐng)域發(fā)展道路上關(guān)于注意力是否能提供有意義解釋的研究主題(Jain&Wallace,2019; Wiegreffe&Pinter,2019; Wallace,2019)。
最近ACL 2020 上關(guān)于 NLP 模型的可解釋性和模型分析的Track 論文,就是人們對(duì)分析方法的持續(xù)興趣的最好例證。
2、為什么重要?
實(shí)際上,當(dāng)前最先進(jìn)的分析方法使用起來(lái)往往是一個(gè)黑匣子。為了開(kāi)發(fā)更好的模型并在現(xiàn)實(shí)世界中應(yīng)用它們,我們需要了解為什么模型會(huì)做出某些決定。然而,我們目前用于解釋模型預(yù)測(cè)的方法仍然十分有限。
3、下一步是什么?
我們需要做出更多的工作來(lái)解釋可視化范圍之外的預(yù)測(cè),因?yàn)檫@些預(yù)測(cè)通常是不可靠的。這個(gè)方向上的一個(gè)重要趨勢(shì)是,更多數(shù)據(jù)集正在提供人為解釋(Camburu等人,2018; Rajani等人,2019; Nie等人,2019)。 雷鋒網(wǎng)雷鋒網(wǎng)雷鋒網(wǎng)
所有文中提到的相關(guān)論文和工作,可以前往原文地址 https://ruder.io/research-highlights-2019/ 獲取。
雷峰網(wǎng)原創(chuàng)文章,未經(jīng)授權(quán)禁止轉(zhuǎn)載。詳情見(jiàn)轉(zhuǎn)載須知。





